Elasticsearch là một công cụ tìm kiếm và phân tích dữ liệu phân tán mã nguồn mở, dựa trên Apache Lucene, cho phép lưu trữ, tìm kiếm và phân tích dữ liệu lớn với tốc độ nhanh và hiệu quả. Được phát triển bởi Elastic bằng ngôn ngữ Java, Elasticsearch thường được sử dụng trong các ứng dụng yêu cầu tính năng tìm kiếm mạnh mẽ, phân tích dữ liệu log và các ứng dụng phân tích dữ liệu lớn.

Nguyên lí hoạt động của Elasticsearch
Elasticsearch hoạt động dựa trên nguyên lý chỉ mục ngược (inverted index), một cấu trúc dữ liệu hiệu quả cho việc tìm kiếm văn bản.
Chỉ mục Ngược: Khi tìm kiếm được thực hiện, Elasticsearch sử dụng chỉ mục ngược để ánh xạ từ các từ khóa (tokens) đến danh sách các tài liệu chứa các từ đó. Điều này cho phép tìm kiếm nhanh chóng và chính xác các tài liệu dựa trên từ khóa tìm kiếm.
Shard và Replica : Dữ liệu trong Elasticsearch được chia thành các phần nhỏ gọi là shards. Mỗi shard lưu trữ một phần của chỉ mục và có thể hoạt động độc lập. Các bản sao của shards, gọi là replica, giúp tăng cường độ tin cậy và khả năng mở rộng. Các bản sao giúp đảm bảo rằng dữ liệu không bị mất và tìm kiếm vẫn hoạt động ngay cả khi một node gặp sự cố.
Một số khái niệm cơ bản của Elasticsearch
Index : Là một tập hợp các tài liệu có cấu trúc tương tự. Trong Elasticsearch, dữ liệu được tổ chức thành các chỉ mục để dễ dàng tìm kiếm và quản lý. Mỗi chỉ mục có thể chứa hàng triệu tài liệu. (index trong Elasticsearch có thể được so sánh với table trong cơ sở dữ liệu quan hệ)
Document : Là đơn vị cơ bản của dữ liệu trong Elasticsearch, thường được lưu trữ dưới dạng JSON. Một tài liệu chứa các trường (fields) và giá trị (values) tương ứng, và nó là đối tượng mà bạn tìm kiếm hoặc thao tác trong Elasticsearch.
Field : Là một thuộc tính của tài liệu, tương tự như một cột trong cơ sở dữ liệu quan hệ. Mỗi field có thể chứa dữ liệu kiểu văn bản, số, ngày tháng, v.v.
Shard : Là một phần nhỏ của chỉ mục. Mỗi chỉ mục được chia thành nhiều shards để phân phối dữ liệu và xử lý tìm kiếm. Shard có thể hoạt động độc lập và lưu trữ một phần của dữ liệu chỉ mục.
Node : là một máy chủ đơn lẻ trong cluster Elasticsearch. Mỗi node lưu trữ một phần của dữ liệu và có thể xử lý các yêu cầu tìm kiếm. Các node có thể hoạt động độc lập hoặc phối hợp với nhau trong một cluster.
Cluster : là tập hợp các nodes (máy chủ) làm việc cùng nhau để lưu trữ và xử lý dữ liệu. Mỗi cluster được xác định bởi một tên chung và các nodes trong cluster có thể chia sẻ dữ liệu và tải công việc với nhau.
Ưu và nhược điểm của Elasticsearch
Ưu điểm
- Cho phép tìm kiếm và truy xuất dữ liệu nhanh chóng, đặc biệt là khi xử lý lượng dữ liệu lớn.
- Cung cấp công cụ mạnh mẽ để phân tích và truy xuất dữ liệu một cách linh hoạt và hiệu quả.
- Elasticsearch có khả năng mở rộng tốt, cho phép mở rộng cụm lên đến hàng nghìn node mà vẫn duy trì được hiệu suất tốt.
Nhược điểm
Đôi khi việc quản lý và cấu hình Elasticsearch có thể đòi hỏi kiến thức kỹ thuật sâu và kinh nghiệm. Để đạt hiệu suất tốt, Elasticsearch yêu cầu tài nguyên phần cứng và mạng đáng kể. Trong một số trường hợp như xử lý tập dữ liệu lớn và truy vấn phức tạp đòi hỏi người dùng cần biết cách tinh chỉnh và tối ưu hóa kỹ thuật.
Cách cài đặt Elasticsearch trong CentOS
Do Elasticsearch chạy trên nền tảng Java nên cần đảm bảo hệ thống có Java, kiểm tra bằng lệnh:
java -version
Nếu chưa cài thì cài đặt java chạy lệnh sau để cài đặt:
sudo yum install java-1.8.0-openjdk
Thiết lập PGP key cho Elasticsearch gõ lệnh sau:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
Tạo / mở file elasticsearch.repo
vi /etc/yum.repos.d/elasticsearch.repo
Thêm nội dung này vào file và lưu lại :
[elasticsearch-8.x]
name=Elasticsearch repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
Gõ lệnh cài đặt
yum install elasticsearch
Cấu hình elasticsearch :
sudo vi /etc/elasticsearch/elasticsearch.yml
Thêm các config sau:
network.host: 0.0.0.0
http.port: 9200
# thiết lập chỉ 1 server, hủy kiểm tra bootstrap
discovery.type: single-node
Kích hoạt dịch vụ Elasticsearch
systemctl enable elasticsearch.service
systemctl start elasticsearch.service
Kiểm tra :
Gõ lệnh
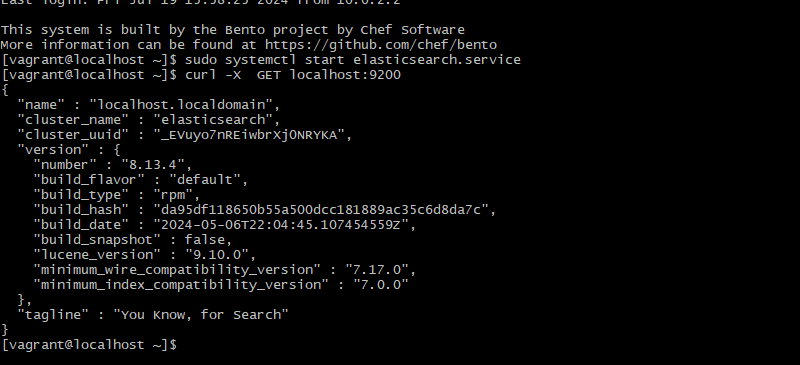
curl -X GET localhost:9200
Nếu hiện ra như sau nghĩa là đã cài đặt thành công:
Cách cài đặt Kibana trong CentOS
Tải Về Gói Cài Đặt Kibana:
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.13.4-x86_64.rpm
Cài Đặt Gói Kibana:
sudo rpm -i kibana-8.13.4-x86_64.rpm
Chỉnh Sửa Tập Tin Cấu Hình:
sudo vi /etc/kibana/kibana.yml
Thêm hoặc sửa các dòng sau trong tập tin cấu hình kibana.yml:
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://localhost:9200"]
Khởi Động Kibana:
sudo systemctl start kibana
Truy Cập Kibana:
http://<your-server-ip>:5601
Thay <your-server-ip> bằng địa chỉ IP của máy chủ nơi Kibana đang chạy. Bạn sẽ được đưa đến giao diện web của Kibana, nơi bạn có thể bắt đầu cấu hình và sử dụng các tính năng của Kibana để phân tích và trực quan hóa dữ liệu.
Thực hành một số câu lệnh truy vấn cơ bản bằng Kibana:
Mở Dev Tools trong Kibana
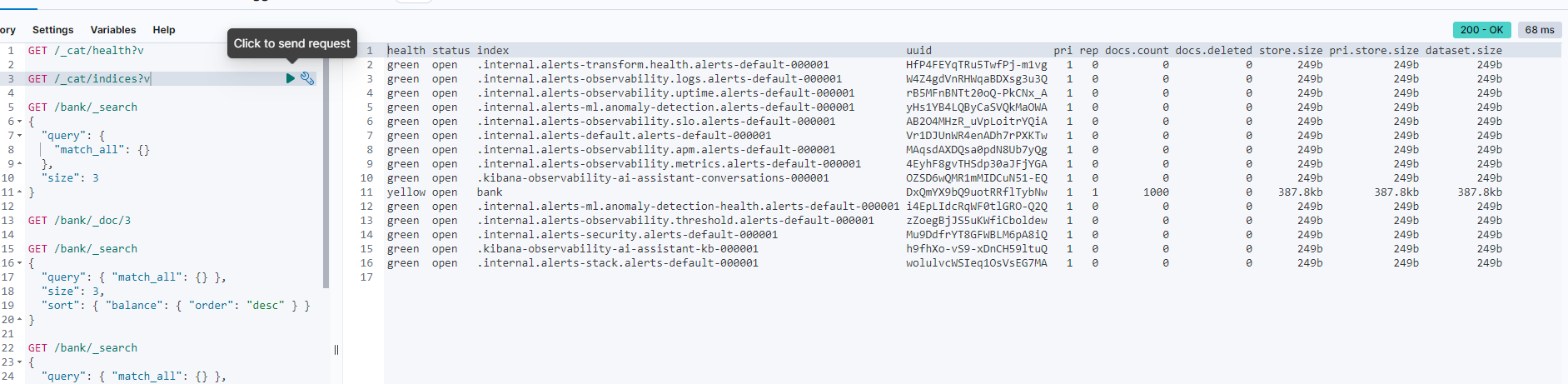
Kiểm tra trạng thái của Elasticsearch:
GET /_cat/health?v

Get danh sách index :
GET /_cat/indices?v
Tạo index:
PUT /name_index?pretty
Tạo index với mapping và settings :
PUT /my_index
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"occupation": {
"type": "text"
}
}
}
}
//number_of_shards: Số lượng phân mảnh của chỉ mục.
//number_of_replicas: Số lượng bản sao của mỗi phân mảnh.
//mappings: Xác định các thuộc tính và kiểu dữ liệu cho các trường trong tài liệu.
Thêm dữ liệu vào index:
POST /name_index/_doc/id_index
{
"name": "John Doe",
"age": 30,
"email": "johndoe@example.com"
}
Chỉnh sửa bản ghi trong index:
PUT /users/_doc/id_index
{
"name": "John Doe 1",
"age": 30,
"email": "johndoe@example.com"
}
Thêm nhiều document vào index cùng 1 lúc:
POST /_bulk
{ "index" : { "_index" : "name_index", "_id" : "9" } }
{ "name" : "John Doe", "age" : 30, "email" : "johndoe@example.com" }
{ "index" : { "_index" : "name_index", "_id" : "6" } }
{ "name" : "Jane Smith", "age" : 25, "email" : "janesmith@example.com" }
{ "index" : { "_index" : "name_index", "_id" : "7" } }
{ "name" : "Alice Brown", "age" : 28, "email" : "alicebrown@example.com" }
Lấy ra toàn bộ document của 1 index:
GET /users/_search
{
"query": {
"match_all": {}
}
}